问题
公司的ERP系统中仓库模块对配件需要使用全文搜索,例如iphonex和iphone x
考虑方案
使用全文搜索引擎ElasticSearch
1.查看安装ElasticSearch对应的java版本要求
具体ElasticSearch对应的java版本查看
1.1 打开elasticsearch版本说明网址,点击你需要查看的版本
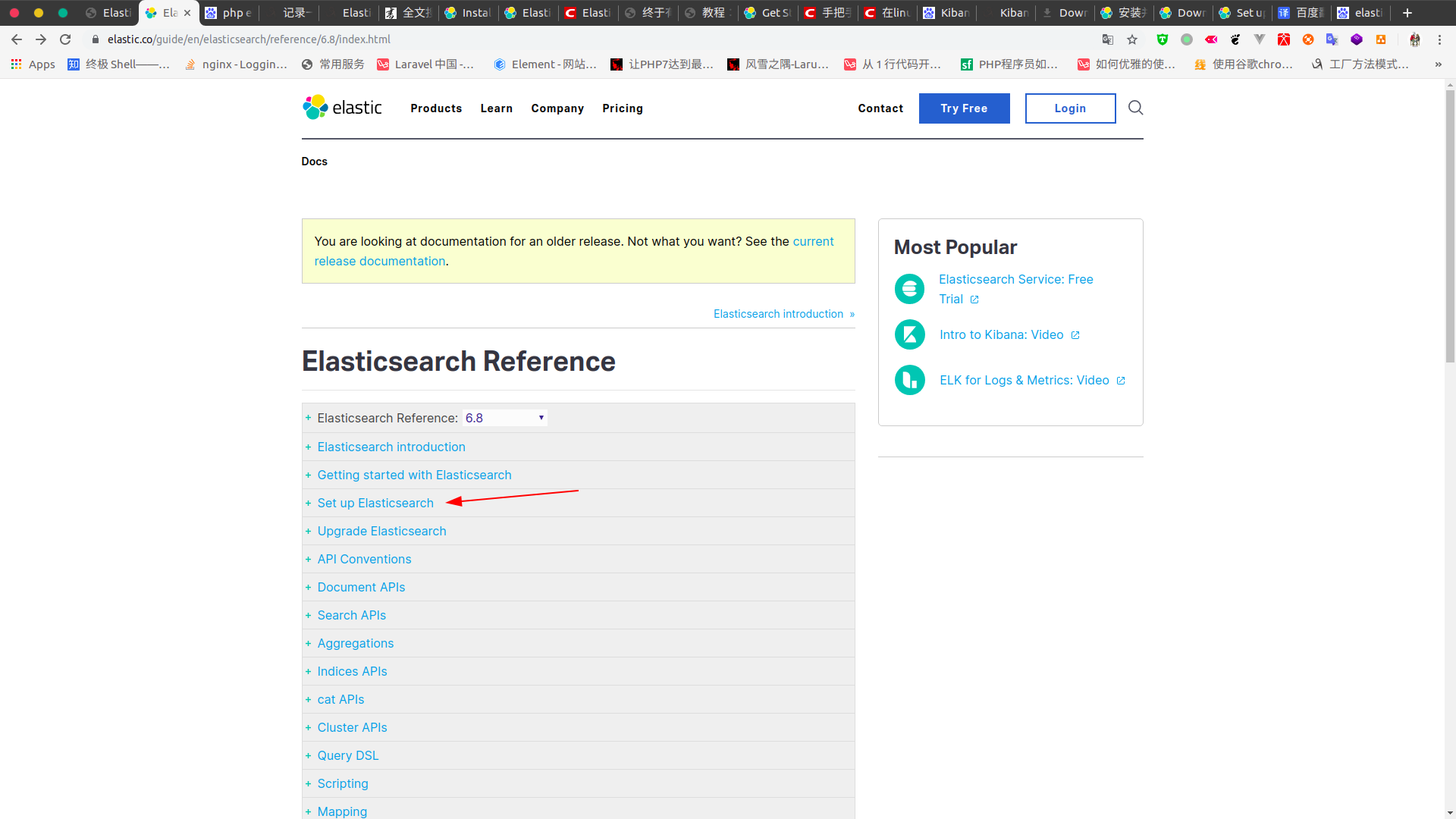
1.2 点击Set up Elasticsearch
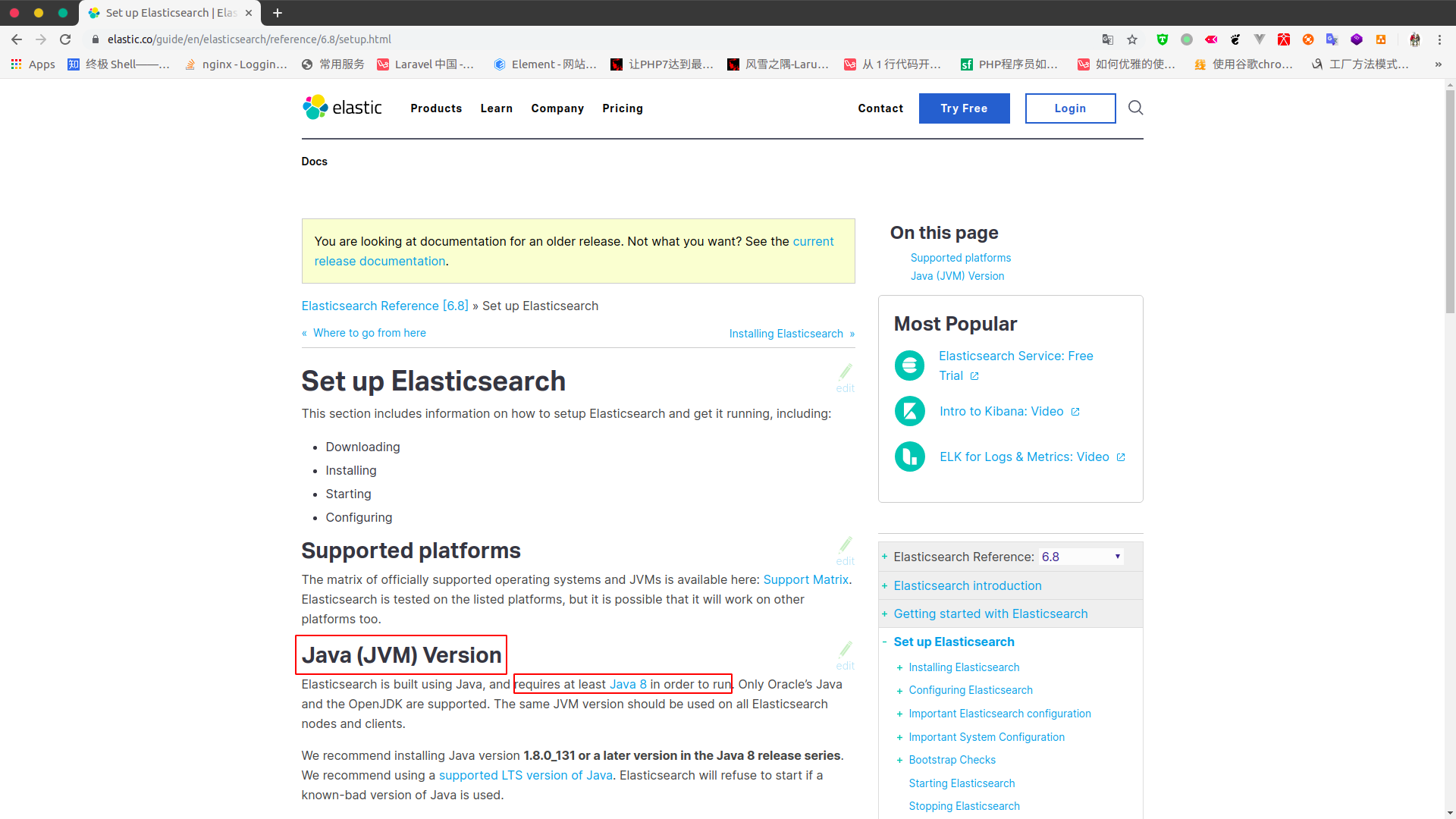
1.3 看到Java (JVM) Version,可以看到需要的java版本
安装
安装java
这里安装java就不做说明了,至于
安装ElasticSearch
跟着官方文档安装 Elastic。直接下载压缩包比较简单。
# 下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.1-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.3.1-linux-x86_64.tar.gz
#接着,进入解压后的目录,运行下面的命令,启动 Elastic。
cd elasticsearch-7.3.1
./bin/elasticsearch
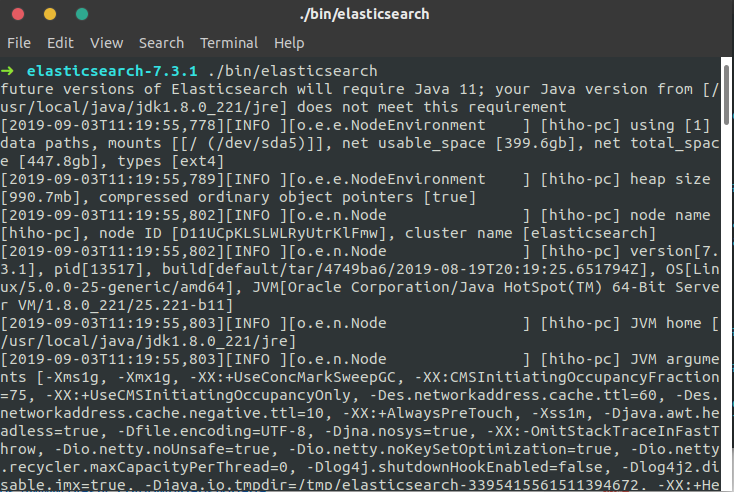
如果一切正常,Elastic 就会在默认的9200端口运行。可以在终端是用curl localhost:9200进行测试
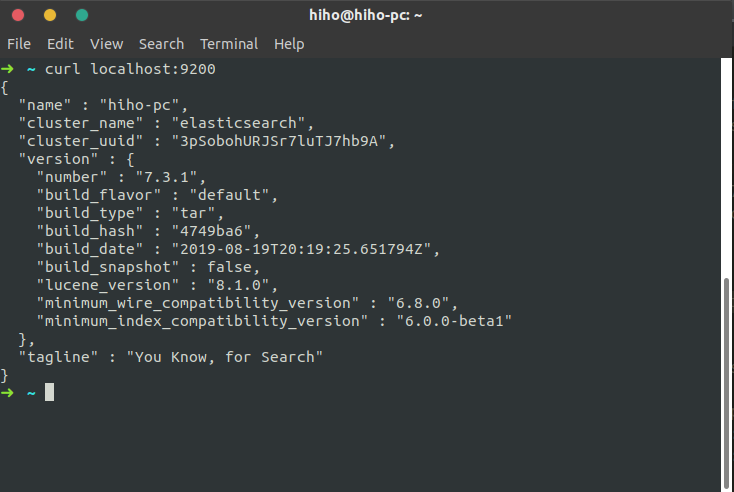
上面代码中,请求9200端口,Elastic 返回一个 JSON 对象,包含当前节点、集群、版本等信息。
2.ElasticSearch核心概念
2.1 Cluster:集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2.2 Node:节点
形成集群的每个服务器称为节点。
2.3 Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。 当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的
2.4 Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。 副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。 当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
2.5 全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。 全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
ES数据架构的主要概念(与关系数据库Mysql对比)
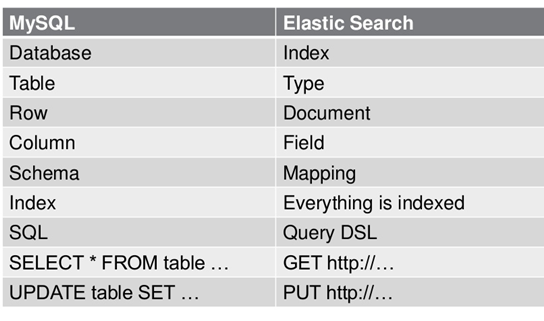
- (1)关系型数据库中的数据库(
DataBase),等价于ES中的索引(Index) - (2)
一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type), - (3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
- (4)在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
- (5)在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
注意:根据规划,
Elastic 6.x版只允许每个 Index 包含一个 Type,7.x版将会彻底移除 Type。
3.修改配置
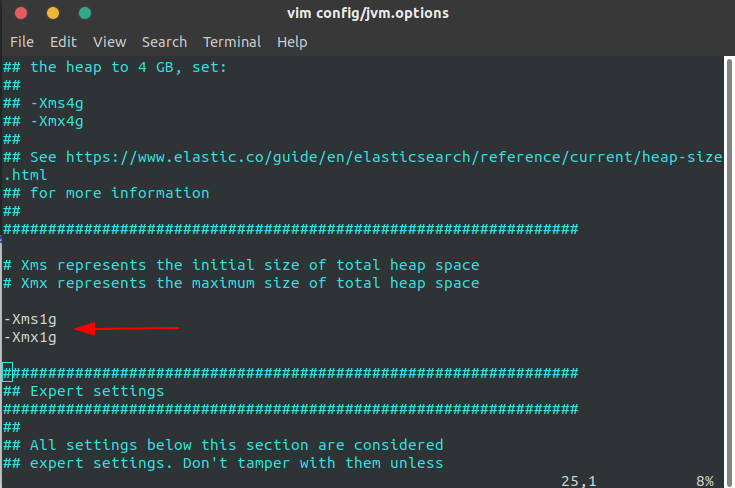
3.1 修改内存
启动es会吃很多内存,内存不够需要修改就找到config文件目录下的jvm.options,打开找到(Xms:代表最小1G,Xmx代表最大1G),修改最小为200m,运行内存会变小。)
vim config/jvm.options
3.2 修改可远程访问Elastic
按下 Ctrl + C,Elastic 就会停止运行。
默认情况下,Elastic 只允许本机访问,如果需要远程访问,可以修改 Elastic 安装目录的config/elasticsearch.yml文件,去掉network.host的注释,将它的值改成0.0.0.0,然后重新启动 Elastic。
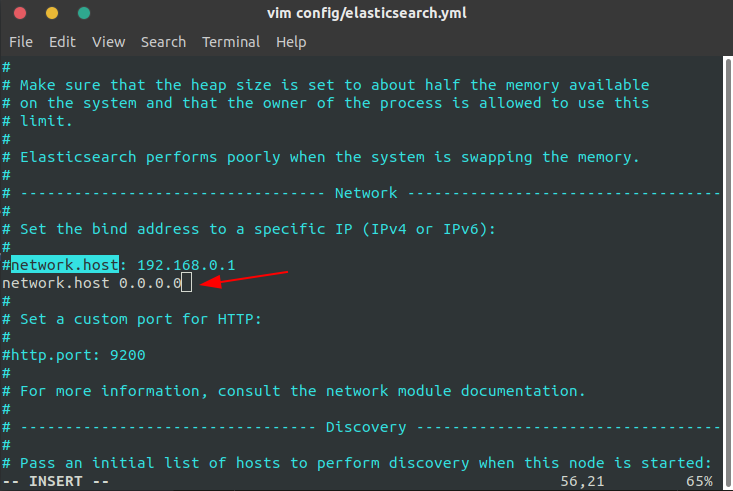
注意:设成0.0.0.0让任何人都可以访问。线上服务不要这样设置,要设成具体的 IP。
3.3 elasticsearch.yml可配置信息
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
4.安装
4.基本操作
Elastic的操作通过rest api来完成,以下操作都将省去,可以使用CURL工具来实行请求,?pretty返回友好的json
curl -X METHOD "http://localhost:9200" -H 'Content-Type: application/json' [-d 'request body']
下面我会以新闻(news)作为例子:
id:其中有新闻title:新闻标题content:新闻内容likes:点赞数
4.1 索引库(Index)操作
4.1.1 列出所有索引
curl -X GET "http://localhost:9200/_cat/indices?v"

#### 4.1.2 创建索引库
curl -X PUT "http://localhost:9200/news?pretty"

#### 4.1.3 删除索引库
curl -X DELETE "http://localhost:9200/news?pretty"

#### 4.1.4 查询索引库是否存在
通过
curl -X --head "http://localhost:9200/news?pretty"
返回状态200则表示存在,404则表示不存在
4.2 文档(Doc)操作
注意:同一个
Index里面的Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
4.2.1 新建文档
新建id为1的document,由于type将被废除,所以规定每个index只包含一个type,统一为_doc
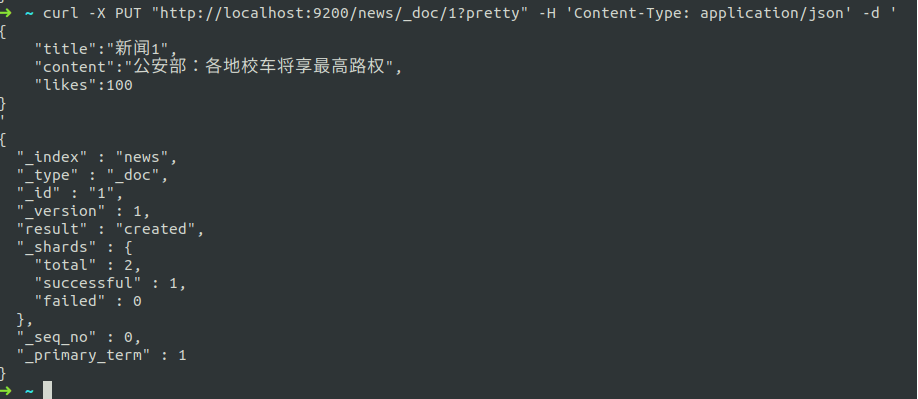
curl -X PUT "http://localhost:9200/news/_doc/1?pretty" -H 'Content-Type: application/json' -d '
{
"title":"新闻1",
"content":"公安部:各地校车将享最高路权",
"likes":100
}
'
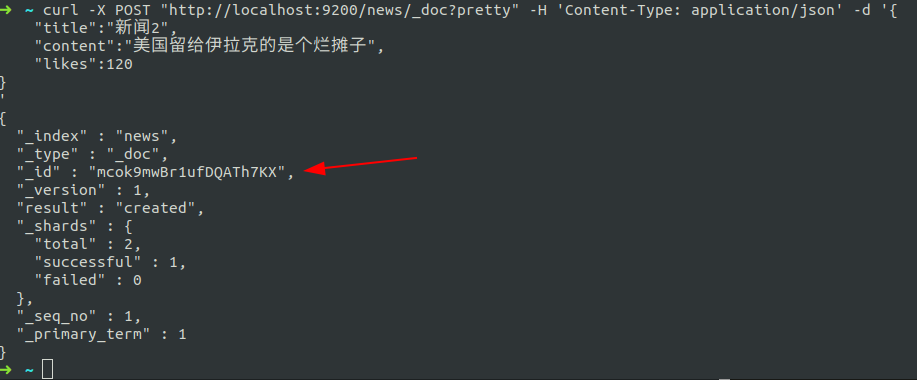
如果使用post并且id留空将会生成一个随机的id
curl -X POST "http://localhost:9200/news/_doc?pretty" -H 'Content-Type: application/json' -d '{
"title":"新闻2",
"content":"美国留给伊拉克的是个烂摊子",
"likes":120
}
'
4.2.2 更新文档
更新文档与新建相同,改变数据即可,或者
curl -X POST "http://localhost:9200/news/_doc/1/_update?pretty" -H 'Content-Type: application/json' -d '
{
"doc":{
"title":"新闻1",
"content":"公安部:各地校车将享最高路权",
"likes":105
}
}
'
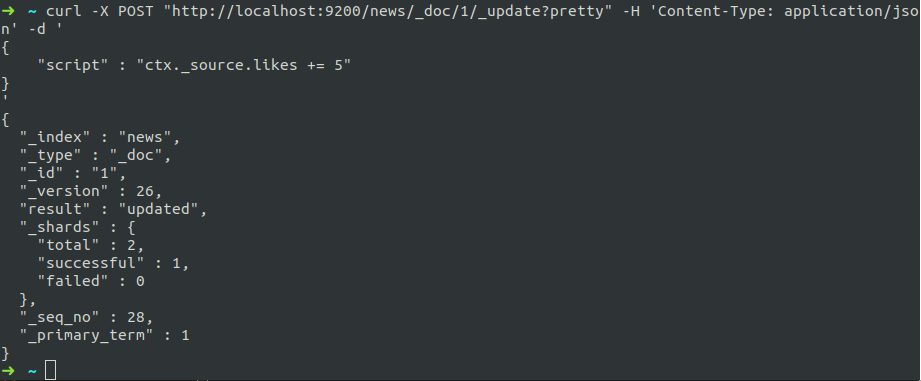
使用简单的脚本更新,这里的ctx._source指向将被修改的文档
curl -X POST "http://localhost:9200/news/_doc/1/_update?pretty" -H 'Content-Type: application/json' -d '
{
"script" : "ctx._source.likes += 5"
}
'
4.2.3 批量操作
批量操作,批量更新id为1和2的文档,注意在postman中body最后必须空一行
POST /news/_doc/_bulk?pretty
{"index":{"_id":"1"}}
{"title": "新闻11 }
{"index":{"_id":"2"}}
{"title": "新闻22", "likes": "110" }
先更新id为1的文档,然后删除id为2的文档
POST /news/_doc/_bulk?pretty
{"update":{"_id":"1"}}
{"doc":{"title":"新闻1 test"}}
{"delete":{"_id":"2"}}
批量操作时其中一个操作失败时,其他操作任然会继续执行,结束时根据执行顺序返回状态。
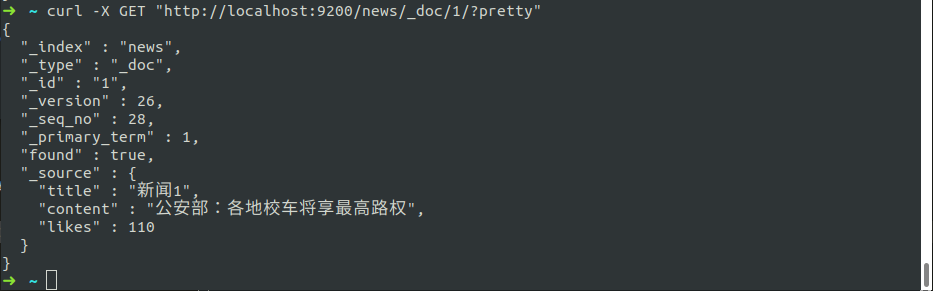
4.2.4 查询某条文档记录
curl -X GET "http://localhost:9200/news/_doc/1/?pretty"
4.2.5 删除文档
curl -X DELETE "http://localhost:9200/news/_doc/1?pretty"
5.查询数据
先准备一个虚拟的银行客户帐户信息数据集,类似这种格式,请右键下载数据集另存为accounts.json
{
"account_number": 0,
"balance": 16623,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": 29,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "bradshawmckenzie@euron.com",
"city": "Hobucken",
"state": "CO"
}
5.1 导入数据集
➜ curl -X POST "http://localhost:9200/bank/_doc/_bulk?pretty&refresh" -H 'Content-Type: application/json' --data-binary "@accounts.json"
➜ curl -X GET "http://localhost:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open news 7yiopoTqS0GSOovbr5RhdA 1 1 1 0 4.6kb 4.6kb
yellow open bank YAg6cDLLSPG38gw4kBK80g 1 1 1000 0 414.2kb 414.2kb
5.2 match_all查询
使用URI搜索,q=*匹配所有,sort=account_number:asc表示按account_number升序排列
GET http://localhost:9200/bank/_search?q=*&sort=account_number:asc&pretty
{
"took" : 63, //耗时,毫秒
"timed_out" : false, //是否超时
"_shards" : { //碎片
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : { //命中
"total" : 1000,
"max_score" : null,
"hits" : [ {
"_index" : "bank",
"_type" : "_doc",
"_id" : "0",
"sort": [0],
"_score" : null,
"_source" : {"account_number":0,"balance":16623,"firstname":"Bradshaw","lastname":"Mckenzie","age":29,"gender":"F","address":"244 Columbus Place","employer":"Euron","email":"bradshawmckenzie@euron.com","city":"Hobucken","state":"CO"}
}, {
"_index" : "bank",
"_type" : "_doc",
"_id" : "1",
"sort": [1],
"_score" : null,
"_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
}, ...
]
}
}
使用json请求体搜索,获取跟上面相同的效果
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}
'
Elastic 默认一次返回10条结果,可以通过size字段改变这个设置。
使用size(默认10)和from限制结果条数,类似mysql的limit和offset;使用_source查询指定字段
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": { "match_all": {} },
"sort": { "balance": { "order": "desc" } },
"from": 10,
"size": 15,
"_source": ["account_number", "balance"]
}
'
5.3 match查询
查询account_number为20的所有账户
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": {
"match": {
"account_number": 20
}
}
}
'
查询address中包含mill单词的所有账户
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": { "match": { "address": "mill" } }
}
'
查询address中包含mill或者lane单词的所有账户
如果有多个搜索关键字, Elastic 认为它们是
or关系。
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": { "match": { "address": "mill lane" } }
}
'
上面代码搜索的是mill or lane。
match_phrase查询,match的变种,查询address中包含mill lane的所有账户
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": { "match_phrase": { "address": "mill lane" } }
}
'
如果要执行多个关键词的and搜索,必须使用布尔查询。
5.4 bool查询
查询address中包含mill和lane单词的所有账户,bool must子句指定所有必须为true的查询才能将文档视为匹配项
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
//"should": [...] 或查询
//"must_not": [...] 都不是
}
}
}
'
组合查询,查询年龄为40并且不住在ID省的客户账户
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
'
5.5 bool过滤器
查询余额在20000到30000(包含)的客户账户
curl -X GET "http://localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d '
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
'
—End—
迭代
- 2019年09月02日 11:51 初稿
参考
- 《Elasticsearch学习,请先看这一篇!》
- 《全文搜索引擎 Elasticsearch 入门教程》
- 《elasticsearch-analysis-ik》
- 《教程:在Ubuntu 18.04.1上安装Elasticsearch》
- 《Kibana(一张图片胜过千万行日志)》
- 《Elasticsearch7.*版本 1.入门》
- 《终于有人把Elasticsearch原理讲透了!》
- 《Elasticsearch-基础介绍及索引原理分析》
- 《Elasticsearch入门教程之安装与基本使用》